A~Eは同じ内容を話しています。何と言っているのでしょうか? A からEにいくほどわかりやすくなります。
説明
まずAは文全体をさかさまに再生したものです。実はこれはさかさ言葉で、「たけやぶやけた」です。しかし、とても日本語には聞こえません。なぜでしょうか?
話し言葉の音声は、舌や唇などの調音器官を動かすことによって作り出されます。例えば「たけやぶやけた」の頭の「た」という音節は、最初に舌先を上の歯茎の裏あたりにくっつけて息をせき止め、次にそれを急速に解放しながら「あ」と発声します。これを逆再生すると、まず「あ」という部分が来て、最後に徐々に舌先が歯茎の裏に近づいていくことになります。これはもはや「た」ではありません。強いて言えば、「ta」の逆、つまり「at」のような感じになります。したがって、さかさ言葉の音声を逆再生すると、仮名を逆から読んだようには聞こえず、むしろローマ字で書いたものを逆から読んだものに近いように聞こえるのです。これでは日本語には聞こえませんね。
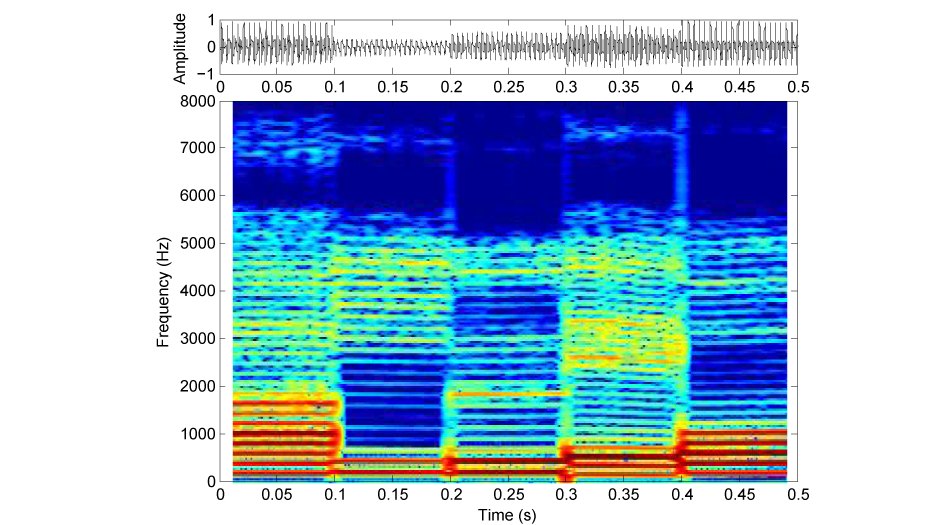
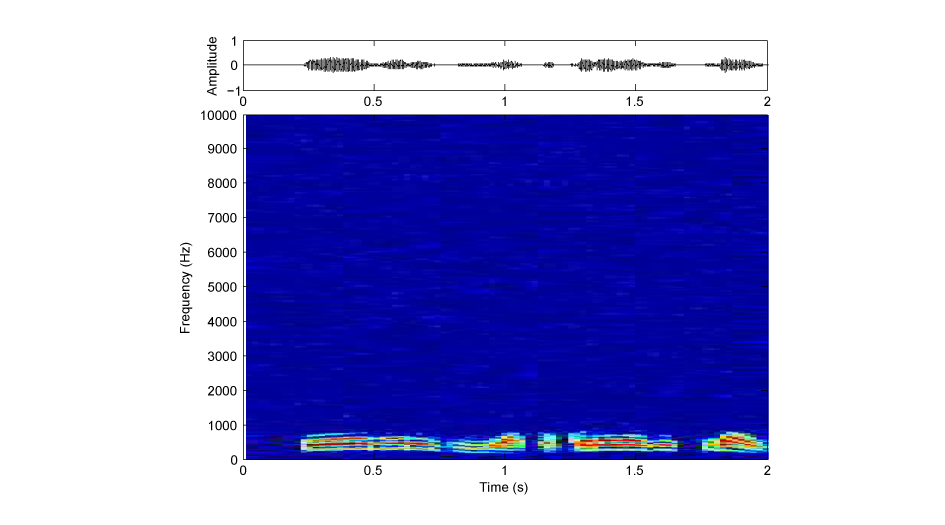
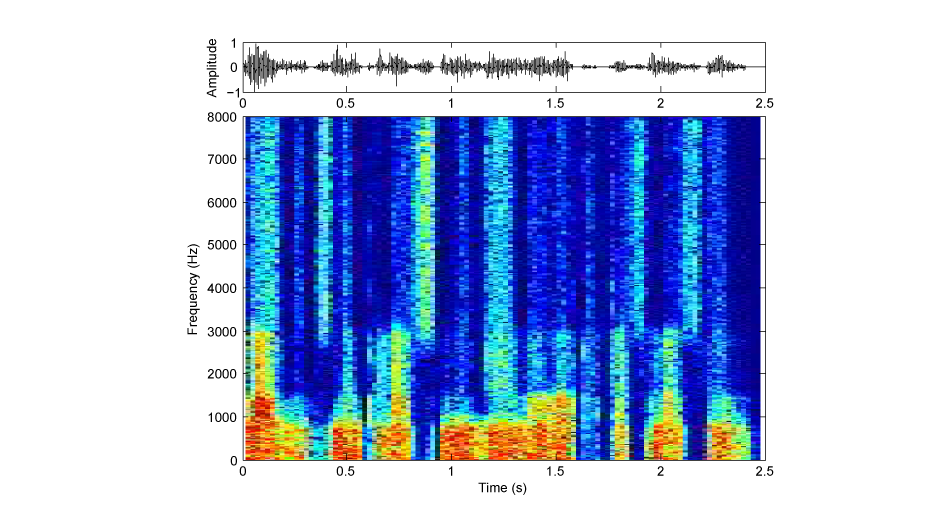
B〜Eは、文を短い区間に区切り、それぞれを時間的に逆転してあります(図1:もとの文、図2:全体逆転(Aの音)、図3:局所逆転(Bの音)の、振幅波形(上段)とサウンドスペクトログラム(下段))。区間の長さは、B: 100 ms、C: 75 ms、D: 50 ms、E: 25 msです。DやEでは、何を言っているか聞き取れるのではないでしょうか。
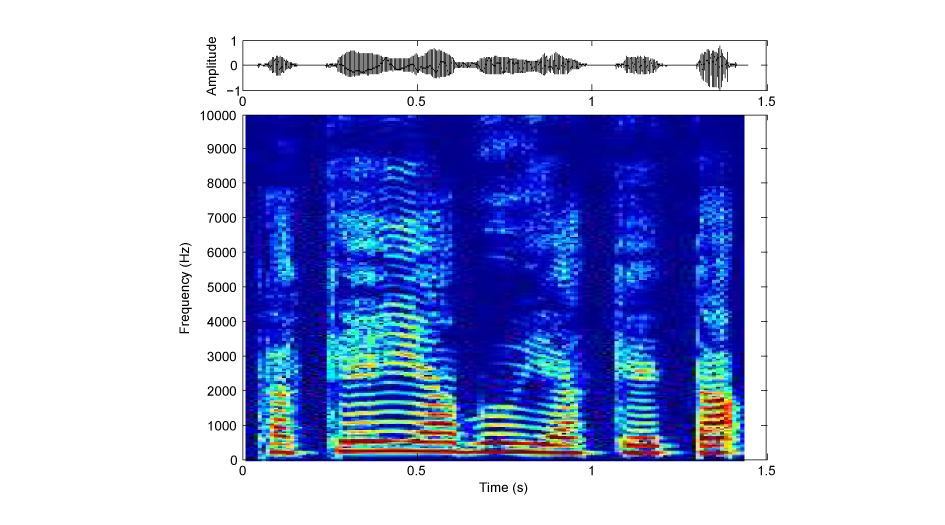
図1:もとの文
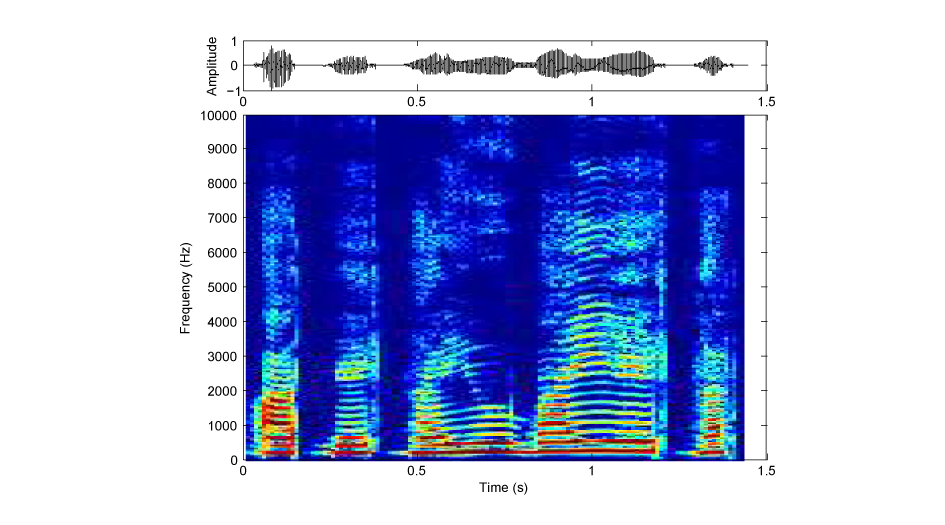
図2:全体逆転(Aの音)
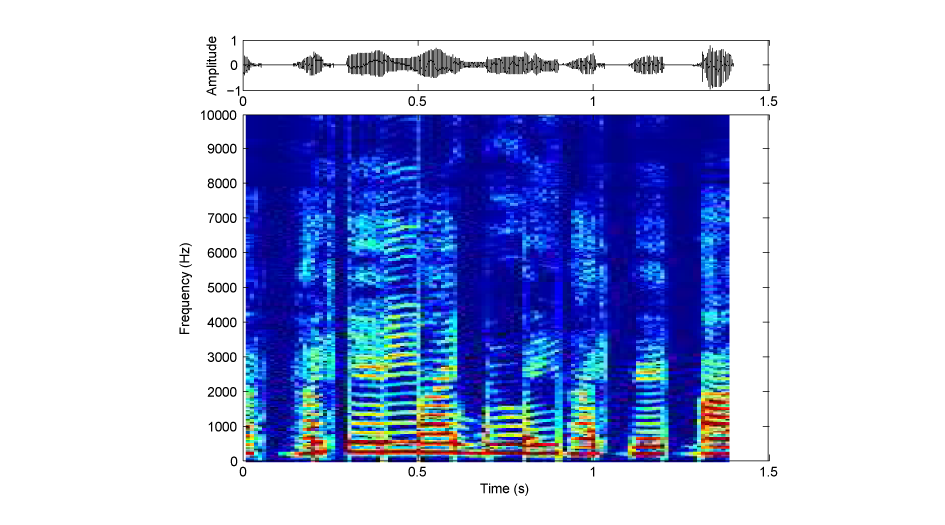
図3:局所逆転(Bの音)
母音や子音は調音器官の動きによって生成されるので、その動きを反映したスペクトルや振幅の変化の仕方が聞き取る上での手がかりとなります。その変化は場合によっては非常に速く、Eの25 msよりも短い範囲で生じるものもあります。声を短い区間で逆転させることは、このような特徴を壊すことになります。それにもかかわらず何を言っているか聞き取れるということは、その区間の長さよりも長い、ゆるやかな変化の中に、母音や子音の識別に必要な情報が含まれているということを意味しています。
このことは、連続聴効果(音韻修復)のデモで、音の一部が欠落しても前後の情報から補完できることと同様、人の話し声が時間的に冗長なものであることを物語っています。(ただし、短い時間内の速い変化が話し声の知覚に役立たないということを示すものではありません。)
(『音のイリュージョン』p. 30-31)
参考文献
- Saberi, K. and Perrott, D.R.: Cognitive restoration of reversed speech. Nature 398, 760, 1999.
- 「音のイリュージョン ― 知覚を生み出す脳の戦略 ―」 柏野牧夫著 岩波書店 2010年
デモについて
- デモの操作方法については、使用方法のページをごらんください。
- 錯聴デモを使用される際には、耳にダメージを与えないよう、お使いのデバイスの音量設定を最適な状態にしてからおためしください。