Aの再生ボタン を押すと雑音のような音が聞こえてきますが、実は何かを話しています。何と言っているのでしょう(日本語です!)。何度か聞いてみてもわからないときは、Bを聞いてから、もう一度Aを聞いてみましょう。
説明
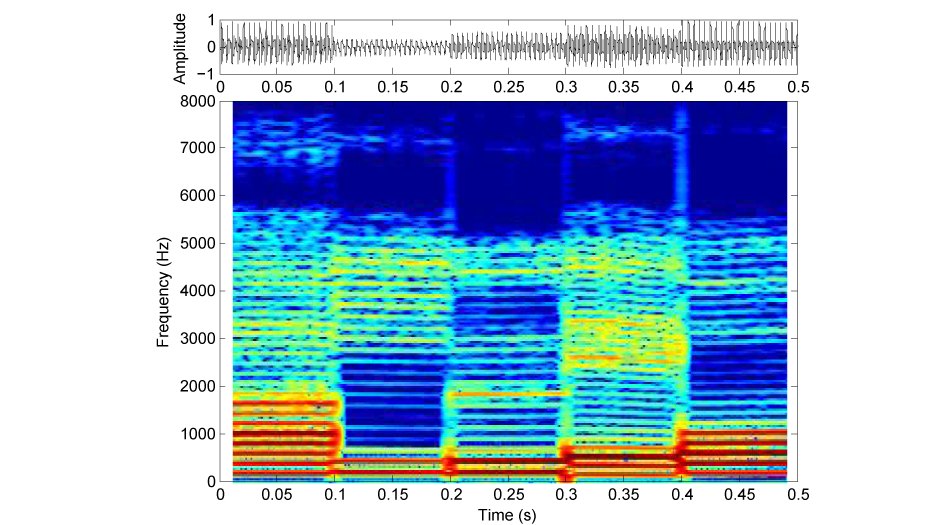
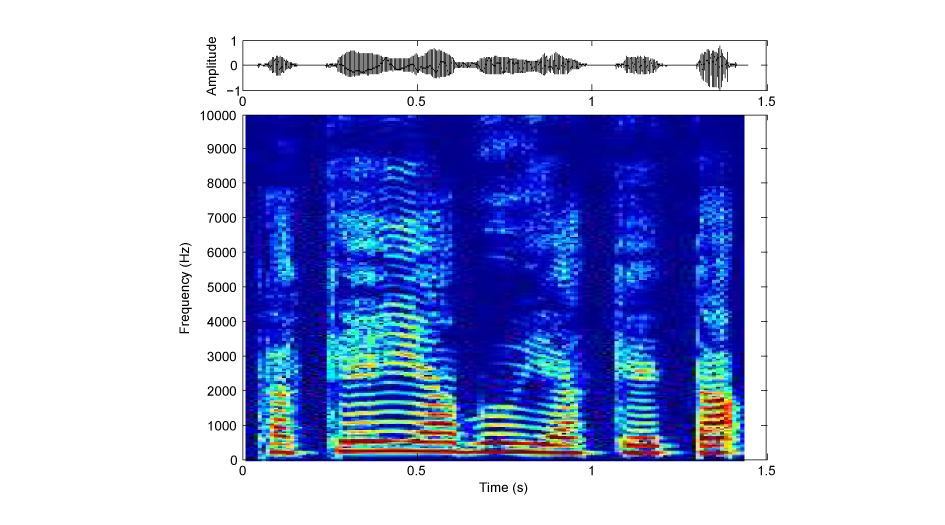
この音声は、話し声を4つの周波数帯域に分割し、それぞれの帯域の振幅包絡を抽出して、同じ帯域の雑音にその振幅包絡を与え、最後に4つの帯域の雑音を足し合わせたものです。要するに、スペクトルの細かい特徴を破壊した、いわば粗いモザイクをかけた映像のような音声になっています(図1:音A(加工音声)、図2:音B(原音声)の、振幅波形(上段)とサウンドスペクトログラム(下段))。
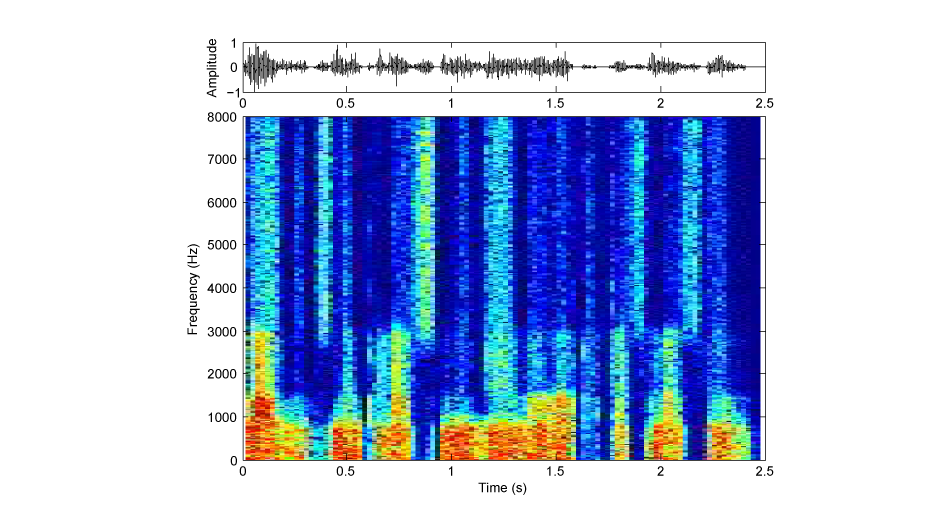
図1 :音A(加工音声)
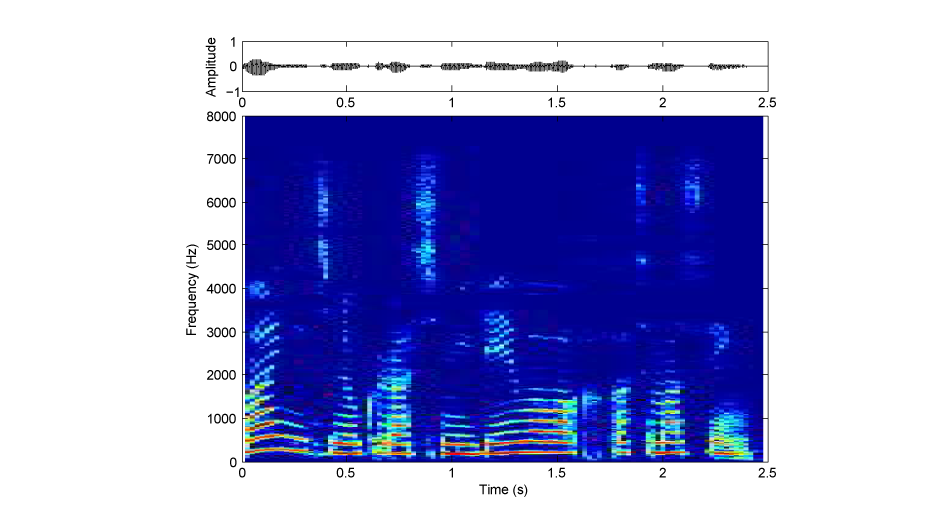
図2:音B(原音声)
もともと、この音声は、人工内耳装用者の聞こえ方を模擬するために開発されました。このように非常に粗い情報だけでも、ある程度声の聞き取りが可能というのがこのデモのひとつのメッセージです。
もうひとつのメッセージは、仮に最初何と言っているかわからなくても、いったん気づいてしまうと、もはやそのようにしか聞こえないほど、声を聞き取る上でトップダウンの効果は強力だということです。
参考文献
- Shannon, R.V., Zeng, F.G., Kamath, V., Wygonski, J., and Ekelid, M.: Speech recognition with primarily temporal cues. Science, 270, 303-304, 1995.
- 力丸 裕: 劣化雑音音声の聞こえ, 日本音響学会誌, 61(5), 273-278, 2005.
- 「音のイリュージョン ― 知覚を生み出す脳の戦略 ―」 柏野牧夫著 岩波書店 2010年
デモについて
- デモの操作方法については、使用方法のページをごらんください。
- 錯聴デモを使用される際には、耳にダメージを与えないよう、お使いのデバイスの音量設定を最適な状態にしてからおためしください。